




Oozie: Scheduling Coordinator/Bundle jobs for Hive partitioning and ElasticSearch indexing
Posted by Jai on May 28, 2014
This post covers to use Oozie to schedule Hive add partition every hour with the help of Coordinator jobs and to automatically update the ElasticSearch data served to customer based on nightly jobs using Bundle jobs functionality. The automated procedure using oozie jobs will help to update the statistical data used on website to display product views count and top search query string.
In continuation to the previous posts on
- Customer product search clicks analytics using big data,
- Flume: Gathering customer product search clicks data using Apache Flume,
- Hive: Query customer top search query and product views count using Apache Hive,
- ElasticSearch-Hadoop: Indexing product views count and customer top search query from Hadoop to ElasticSearch
As described in earlier posts, the hive partitioning strategy is added based on current time and accordingly the elasticsearch indexing based on analytic data also. We will cover here to automate the process using Oozie to add hive partition once data is available in hadoop directory.
Oozie
Oozie is a workflow scheduler system to manage Apache Hadoop jobs.
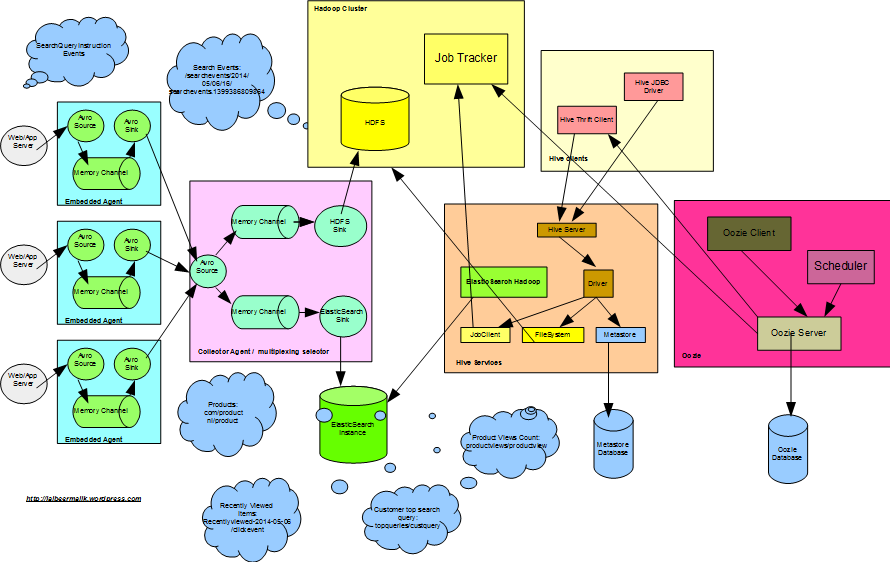
Oozie Server setup
For testing purpose, the LocalOozie is used to startup oozie server JaiLocalOozie.java ,
public class JaiLocalOozie extends LocalOozie {
public synchronized static void start() throws Exception {
...
//Control what servlet you want to start
//Control how the embedded servlet container be started.
//Control acces to container host/port information used in callback url etc.
container = new EmbeddedServletContainer("oozie");
container.addServletEndpoint("/callback", CallbackServlet.class);
container.addServletEndpoint("/" + RestConstants.VERSIONS, VersionServlet.class);
container.addServletEndpoint("/v0/job/*", V0JobServlet.class);
container.addServletEndpoint("/v1/job/*", V1JobServlet.class);
container.addServletEndpoint("/v2/job/*", V2JobServlet.class);
container.addServletEndpoint("/v1/jobs", V1JobsServlet.class);
container.addServletEndpoint("/v2/jobs", V1JobsServlet.class);
...
}
...
}
For testing purpose, oozie home, oozie workflow files are setup at the starting of the test OozieJobsServiceImpl.java
public void setup() {
...
File oozieHome = new File("target/ooziehome");
File oozieData = new File(oozieHome, "data");
System.setProperty(Services.OOZIE_HOME_DIR, oozieHome.getAbsolutePath());
System.setProperty("oozie.data.dir", oozieData.getAbsolutePath());
//Make sure to call all relevant config files.
File oozieActionConf = new File(oozieConf, "action-conf");
oozieActionConf.mkdir();
FileUtils.copyFileToDirectory(new ClassPathResource("hive/hive-site.xml").getFile(), oozieActionConf);
...
...
}
Oozie Coordinator
We will use Oozie Coordinator to schedule hourly jobs
Hadoop Data
The sample data stored in hadoop is,
# hdfs://localhost.localdomain:54321/searchevents/2014/05/06/16/searchevents.1399386809864
{"eventid":"e8470a00-c869-4a90-89f2-f550522f8f52-1399386809212-72","hostedmachinename":"192.168.182.1334","pageurl":"http://jaibigdata.com/0","customerid":72,"sessionid":"7871a55c-a950-4394-bf5f-d2179a553575","querystring":null,"sortorder":"desc","pagenumber":0,"totalhits":8,"hitsshown":44,"createdtimestampinmillis":1399386809212,"clickeddocid":"23","favourite":null,"eventidsuffix":"e8470a00-c869-4a90-89f2-f550522f8f52","filters":[{"code":"searchfacettype_brand_level_2","value":"Apple"},{"code":"searchfacettype_color_level_2","value":"Blue"}]}
{"eventid":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0-1399386809743-61","hostedmachinename":"192.168.182.1330","pageurl":"http://jaibigdata.com/0","customerid":61,"sessionid":"78286f6d-cc1e-489c-85ce-a7de8419d628","querystring":"queryString59","sortorder":"asc","pagenumber":3,"totalhits":32,"hitsshown":9,"createdtimestampinmillis":1399386809743,"clickeddocid":null,"favourite":null,"eventidsuffix":"2a4c1e1b-d2c9-4fe2-b38d-9b7d32feb4e0","filters":[{"code":"searchfacettype_age_level_2","value":"0-12 years"}]}
hive partition
Based on above location “/searchevents/2014/05/06/16/”, we will pass following param values (DBNAME=search, TBNAME=search_clicks, YEAR=2014, MONTH=05, DAY=06, HOUR=16).
ALTER TABLE ${hiveconf:TBNAME} ADD IF NOT EXISTS PARTITION(year='${hiveconf:YEAR}', month='${hiveconf:MONTH}', day='${hiveconf:DAY}', hour='${hiveconf:HOUR}') LOCATION "hdfs:///searchevents/${hiveconf:YEAR}/${hiveconf:MONTH}/${hiveconf:DAY}/${hiveconf:HOUR}/";
Add workflow App to Oozie
String userName = System.getProperty("user.name");
String workFlowRoot = hadoopClusterService.getHDFSUri() + "/usr/"+ userName + "/oozie/wf-hive-add-partition";
...
File wfDir = new ClassPathResource("oozie/wf-hive-add-partition").getFile();
FileUtil.copy(wfDir, fs, workFlowRootPath, false, new Configuration());
FileUtil.copy(new ClassPathResource("hive/hive-site.xml").getFile(),fs, new Path(workFlowRoot), false, new Configuration());
...
Coordinator App config
coord-app-hive-add-partition.xml shows full configuration for the coordinator app
<coordinator-app name="add-partition-coord" frequency="${coord:hours(1)}" start="${jobStart}" end="${jobEnd}" timezone="UTC" xmlns="uri:oozie:coordinator:0.1">
<datasets>
<dataset name="searchevents" frequency="${coord:hours(1)}" initial-instance="${initialDataset}" timezone="Europe/Amsterdam">
<uri-template>hdfs://localhost.localdomain:54321/searchevents/${YEAR}/${MONTH}/${DAY}/${HOUR}</uri-template>
</dataset>
</datasets>
...
<action>
<workflow>
<app-path>${workflowRoot}/hive-action-add-partition.xml</app-path>
...
...
</workflow>
</action>
</coordinator-app>
The dataset control if the directory exists, the hive action will be called and new partition will be added. You can also use done-flag to control when the directory is ready with data.
As configured, the job runs every hour. Make sure to configure timeout etc. settings to control it better.
Coordinator App Hive Action
Check the hive action configurations hive-action-add-partition.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="hive-add-partition-searchevents-wf">
<start to="hive-add-partition-searchevents" />
<action name="hive-add-partition-searchevents" retry-max="1" retry-interval="1">
<hive xmlns="uri:oozie:hive-action:0.4">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
...
...
<script>add_partition_hive_searchevents_script.q</script>
<param>YEAR=${YEAR}</param>
<param>MONTH=${MONTH}</param>
<param>DAY=${DAY}</param>
<param>HOUR=${HOUR}</param>
</hive>
<ok to="end" />
<error to="fail" />
</action>
...
</workflow-app>
Testing
You can add the workflow files to existing standalone oozie instance also. The job.properties files is used to set the job configuration. For testing purpose we are explicitly passing the param
...
String oozieURL = System.getProperty("oozie.base.url");
OozieClient client = new OozieClient(oozieURL);
Properties conf = client.createConfiguration();
conf.setProperty(OozieClient.COORDINATOR_APP_PATH, workFlowRoot + "/coord-app-hive-add-partition.xml");
conf.setProperty("nameNode", hadoopClusterService.getHDFSUri());
conf.setProperty("jobTracker", hadoopClusterService.getJobTRackerUri());
conf.setProperty("workflowRoot", workFlowRoot);
Date nowMinusOneMin = new DateTime().minusMinutes(1).toDate();
Date now = new DateTime().toDate();
conf.setProperty("jobStart", DateUtils.formatDateOozieTZ(nowMinusOneMin));
conf.setProperty("jobEnd", DateUtils.formatDateOozieTZ(new DateTime().plusHours(2).toDate()));
conf.setProperty("initialDataset", DateUtils.formatDateOozieTZ(now));
conf.setProperty("tzOffset", "2");
// submit and start the workflow job
String jobId = client.submit(conf);
...
Oozie Bundle
We will use Oozie Bundle to combine creating hive table based on hive table and then indexing that to ElasticSearch.
Create bundle job, to include both creating top search query string analytical data in hive and then indexing same in ElasticSearch. Check full configurations under load-and-index-customerqueries-bundle-configuration.xml
...
<bundle-app name='BundleApp-LoadAndIndexTopCustomerQueries' xmlns='uri:oozie:bundle:0.2'>
<controls>
<kick-off-time>${jobStart}</kick-off-time>
</controls>
<coordinator name='CoordApp-LoadCustomerQueries' >
<app-path>${coordAppPathLoadCustomerQueries}</app-path>
</coordinator>
<coordinator name='CoordApp-IndexTopQueriesES' >
<app-path>${coordAppPathIndexTopQueriesES}</app-path>
</coordinator>
</bundle-app>
....
<coordinator-app name="CoordApp-LoadCustomerQueries" frequency="${coord:days(1)}" start="${jobStart}" end="${jobEnd}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
...
<action>
<workflow>
<app-path>${workflowRoot}/hive-action-load-customerqueries.xml
</app-path>
</workflow>
</action>
</coordinator-app>
...
<coordinator-app name="CoordApp-IndexTopQueriesES" frequency="${coord:days(1)}" start="${jobStartIndex}" end="${jobEnd}" timezone="UTC" xmlns="uri:oozie:coordinator:0.2">
...
<action>
<workflow>
<app-path>${workflowRoot}/hive-action-index-es-topqueries.xml
</app-path>
</workflow>
</action>
</coordinator-app>
As configured, the jobs run on daily basis with frequency 1 day.
Testing
For testing purpose set the job properties explicitly, OozieJobsServiceImpl.java
String oozieURL = System.getProperty("oozie.base.url");
OozieClient client = new OozieClient(oozieURL);
Properties conf = client.createConfiguration();
conf.setProperty(OozieClient.BUNDLE_APP_PATH, workFlowRoot + "/load-and-index-customerqueries-bundle-configuration.xml");
conf.setProperty("coordAppPathLoadCustomerQueries", workFlowRoot + "/coord-app-load-customerqueries.xml");
conf.setProperty("coordAppPathIndexTopQueriesES", workFlowRoot + "/coord-app-index-topqueries-es.xml");
conf.setProperty("nameNode", hadoopClusterService.getHDFSUri());
conf.setProperty("jobTracker", hadoopClusterService.getJobTRackerUri());
conf.setProperty("workflowRoot", workFlowRoot);
String userName = System.getProperty("user.name");
String oozieWorkFlowRoot = hadoopClusterService.getHDFSUri() + "/usr/" + userName + "/oozie";
conf.setProperty("oozieWorkflowRoot", oozieWorkFlowRoot);
Date now = new Date();
conf.setProperty("jobStart", DateUtils.formatDateOozieTZ(new DateTime(now).minusDays(1).toDate()));
conf.setProperty("jobStartIndex", DateUtils.formatDateOozieTZ(new DateTime(now).minusDays(1).plusMinutes(1).toDate()));
conf.setProperty("jobEnd", DateUtils.formatDateOozieTZ(new DateTime().plusDays(2).toDate()));
conf.setProperty("initialDataset", DateUtils.formatDateOozieTZ(now));
conf.setProperty("tzOffset", "2");
// submit and start the workflow job
String jobId = client.submit(conf);
In the example, currently there is no direct dependency created between the bundle jobs. You can configure different schedule time for the coordinated jobs to remove dependency or you can also extend it to create temp file once hive table is done and only then indexing to elasticsearch job will start.
Sample data
Customer top search query string sample data in hive table “search_customerquery” is,
# id, querystring, count, customerid 61_queryString59, queryString59, 5, 61 298_queryString48, queryString48, 3, 298 440_queryString16, queryString16, 1, 440 47_queryString85, queryString85, 1, 47
And the corresponding sample data as index under elasticsearch,
{id=474_queryString95, querystring=queryString95, querycount=10, customerid=474}
{id=482_queryString43, querystring=queryString43, querycount=5, customerid=482}
{id=482_queryString64, querystring=queryString64, querycount=7, customerid=482}
{id=483_queryString6, querystring=queryString6, querycount=2, customerid=483}
{id=487_queryString86, querystring=queryString86, querycount=111, customerid=487}
{id=494_queryString67, querystring=queryString67, querycount=1, customerid=494}
Hope this helps you to get hands on the oozie workflow scheduling and automating the analytic process.

Spark: Real time analytics for big data for top search queries and top product views « Jai’s Weblog – Tech, Security & Fun… said
[…] Oozie: Scheduling Co… on ElasticSearch-Hadoop: Indexing… […]
HBase: Generating search click events statistics for customer behavior « Jai’s Weblog – Tech, Security & Fun… said
[…] Spark: Real time ana… on Oozie: Scheduling Coordinator/… […]
Exploring Enterprise Search Solution Critical Capabilities « Jai’s Weblog – Tech, Security & Fun… said
[…] Oozie: Scheduling Coordinator/Bundle jobs for Hive partitioning and ElasticSearch indexing […]