




Exploring Enterprise Search Solution Critical Capabilities
Posted by Jai on March 30, 2023
In this series of blog posts we will review the enterprise search solution capabilities, available software solutions, from basic to advanced search capabilities along with using AI/ML models to achieve both consumer and business value. We will also cover the search solution for healthcare domain common user interactions, domain dataset and ML alignments. In this post we will cover the critical enterprise search solution capabilities on high level.

History
A long has changed in the search solution capabilities since the initial blog posts shared here in this blog for ElasticSearch capabilities. Additionally using Elasticsearch for user behavior clickstream data with Hadoop big data capabilities to process those information. A quick glance at those here,
ElasticSearch
Getting used to Elastic search and having hands directly with different tricks,
Getting started with ElasticSearch
ElasticSearch: Faceted Search for Hierarchical data
ElasticSearch: Text analysis for content enrichment
ElasticSearch: Boosting score for content relevancy
ElasticSearch: Learn Java API usage with test cases
ElasticSearch: Indexing setup using Akka tutorial
ElasticSearch and Hadoop
Exploring user click information with Hadoop system for analytics information,

Customer product search clicks analytics using big data
Flume: Gathering customer product search clicks data using Apache Flume
Oozie: Scheduling Coordinator/Bundle jobs for Hive partitioning and ElasticSearch indexing
Evolving Consumer Search Experience Trends
The technology is changing at fast pace and accordingly the consumer behavior and experience is evolving very fast.
How big impact the Search Experience can have on overall consumer experience is very imminent.
Today, an overwhelming majority of these journeys begin on search engines. However, recent research shows that a pervasive confusion with how search works are having a negative impact on customer experience.
BrandVerity Study Finds 63% of Consumers Are Unaware of How Search Engines Work
Consumer confusion is growing alongside this spend, resulting in 63% of US consumers reporting that they don’t know how search engine results work. Just 37% understand that they’re in fact categorized by a combination of both relevancy and spend. Compounding this issue is the fact that more than one-in-three-consumers state they don’t believe search engines do a good job of labeling ads.
As per the 2022 CX Trends AI Adoption,
So much so that seven out of 10 consumers now agree that AI is good for society.
Chatbots adds to the frustration,
After all, 54% of customers say that their biggest frustration with chatbots is the number of questions they must answer before being transferred to a human agent.
Overall the expectations of improved Customer Experience have increased manifold and accordingly the adoption of AI has increased
Web Search Vs Enterprise Search
Although both web search and enterprise search are powerful ways to deliver the right information when needed, the key difference between two are,
One of the most significant differences between web and enterprise search is who’ll be using them. With web search, end users are the main audience. However, enterprise searches often need to accommodate both end users and client systems within an organization.
Security and Network access another key parameter which differentiate the two. In terms of data ingestion, the two differs much as the target audiences may also differ.
- Index
- Ingest
- Network
- Security
- Search UI
- Search Criteria/Types
Enterprise Search Solution Capabilities
The term “enterprise search” describes the software used to search for information inside a corporate organization. The technology identifies and enables the indexing, searching and display of specific content to authorized users across the enterprise.
An effective enterprise search tool needs to be unified, scalable, flexible, secure, and intuitive and accommodating of today’s user needs. We will explore critical capabilities of such enterprise search solution on high level.
Basic Search Capabilities
Keywords and key phrases are one of the most familiar components of the search experience. Basic text search is key component of such solution.
Based on search results navigating the user using faceting and allowing to filter content based on facet is commonly available. Faceting is a critical capability that allows the user to filter results efficiently based on a specific field. This is especially useful for limiting a search to a facet category.
Text Pre-Processing
Text preprocessing is a method to clean the text data and make it ready to feed data to the model. Text data contains noise in various forms like emotions, punctuation, casing etc. When we talk about Human Language then, there are different ways to say the same thing, And this is only the main problem we have to deal with because machines will not understand words, they need numbers so we need to convert text to numbers in an efficient manner.

There are multiple must have Text Preprocessing capabilities like,
Expand Contractions
Contraction is the shortened form of a word like don’t stands for do not, aren’t stands for are not. Like this, we need to expand this contraction in the text data for better analysis.
The input data can come from any source and we can not control the input, we need to make sure the conversion capability is available in search solution.
Lower Case
If the text is in the same case, it is easy for a machine to interpret the words because the lower case and upper case are treated differently by the machine.
The search solution needs to ensure the casing capability is available.
Remove Punctuations
One of the other text processing techniques is removing punctuations.
All the hyphens, modulus signs, unwanted commas, and full stops etc. are removed from the text.
Word Delimiter
Sometimes it happens that words and digits combine are written in the text which creates a problem for machines to understand, we may need to remove the words.
The search solution should have capability to treat such text different to break the text or replace based on preferences of the system.
Remove Stopwords
Stopwords are the most commonly occurring words in a text which do not provide any valuable information.
For example “they, there, this, where,” etc are some of the stopwords. There can be pre defined bad works specified in the list can also act as input to remove these.
Rephrase Text
we may need to modify some text or change the pattern to a particular string which makes it easy to identify like we can match the pattern of email ids and change it to string like email address.
Stemming
Stemming is a process to reduce the word to its root stem for example run, running, runs, runed derived from the same word as run. basically stemming do is remove the prefix or suffix from word like ing, s, es, etc.
Lemmatization
Lemmatization is similar to stemming, used to stem the words into root word but differs in working. Actually, Lemmatization is a systematic way to reduce the words into their lemma by matching them with a language dictionary.
Remove White spaces
Most of the time text data contain extra spaces or while performing the above preprocessing techniques more than one space is left between the text so we need to control this problem.
The list is only an example of text manipulations at the pre processing time, See many more options for text manipulations.
Search UI Capabilities
The intuitive and easy frontend of any search solution is as important as robust, scalable and capable search backend system. The flexibility to quickly build custom or embedded search experiences using prebuilt, open code components is very important. Enabling users to put a ready-to-use search bar, auto-suggest, filters, faceting, and natural language search to work to give users the modern ease of use they’ve come to expect.
Below some of the key features of such UI capabilitites,
Search-as-you-type
You just start typing & simultaneously relevant options start displaying as suggestions and autocomplete.
Filtering, faceting, sorting
Ability to filter and sort the content on the UI.
Pagination and highlighting
Restricting the number of records on the screen, improving performance by controlling number of records to display are key features of good UI.
Typeahead
Auto-suggest are now standard user expectations in search UI. As users type, the UI suggests what they’re likely to be interested in.
WYSIWYG embedding
This allows implementers to configure a search UI in a web-based administration tool and then “include” it on their site using HTML or JavaScript statements.
Component libraries
Component libraries provide common UI functionality, such as typeahead. These exist in many forms from tag libraries or JavaScript APIs.
Auto-classification
Auto-classification is a more advanced form of typeahead. For example, when a user types “phone,” and then “Electronics” is automatically selected as a category.
Relevance and Ranking
Relevance is the core part of Information Retrieval. Roughly speaking, a relevant search result is one in which a person gets what he/she was searching for. Naively you could go about doing a simple text search over documents and then return results. Obviously it won’t work mainly due to the fact that language can be used to express the same term in many different ways and with many different words.

The search should be adoptive in terms of incorporating different types of relevancy with the searched data,
Recommendations
Based on user behavior of most viewed, most clicked, most bought products the pattern can be derived to show the relevant product to the consumer.
Search system taking into account user context and intent to show relevant documents is very import feature.
Adaptive Relevance
Based on most used queries in the system and relevant documents data, the machine learning adopts to suggest documents. The most the data system have, more adoptive the system becomes over time.
Semantic Search Relevancy
Use the machine learning technology to improve semantic relevance with vector search, support for NLP models, and model management.
Optimizing Relevancy
Easily adjust the recall of your results with precision tuning or lend additional weight or boosts to certain data fields. Add synonyms for common search terms to customize search to business and user requirements.
Allowing business to control system with manually fine tuning the parameters of weight, meta data, business campain focused approach to get better business value.
Dynamic content filtering
Let facets automatically adjust to each query, classifying, reordering, and removing irrelevant filters while allowing users to further narrow their results.
Multi-objective optimization
Multi-Objective Ranking Optimization (MORO) – Learning a ranking model in product search involves satisfying many requirements such as maximizing the relevance of retrieved products with respect to the user query, as well as maximizing the purchase likelihood of these products.
Multi-objective ranking using Constrained Optimization in GBTs shows example details on the same.
Multi-armed bandit
Multi-Armed Bandit (MAB) is a Machine Learning framework in which an agent has to select actions (arms) in order to maximize its cumulative reward in the long term. In each round, the agent receives some information about the current state (context), then it chooses an action based on this information and the experience gathered in previous rounds. At the end of each round, the agent receives the reward associated with the chosen action.
Multi-armed bandits for the Win shows how to use MAB for real business value improvement.
Document Enrichment
Enrichment—things getting better bit by bit until they are almost perfect.

Enrichment At Indexing Time
This enrichment, done at time of index, greatly improves the odds of returning results from keyword search since it now includes looking for synonyms and misspellings for search terms.
You can alter your content and document metadata fields or attributes during the document ingestion process. This feature gives you control over how your documents are treated and ingested
You can manipulate your document fields and content using basic logic. This includes removing values in a field, modifying values in a field using a condition, or creating a field.
Use NLP to enrich document at indexing time,
Named entity recognition (NER)
Most commonly used to detect entities such as People, Places, and Organization information from text, NER can be used to extract key information from text and group results based on that information.
Text classification
Text classification is commonly used for sentiment analysis and can be used for similar tasks, such as labeling content as containing hate speech in public forums, or triaging and labeling support tickets so they reach the correct level of escalation automatically.
Text embedding
Analyzing a text field using a Text embedding model will generate a dense_vector representation of the text.
Enrichment at Query Time
We can correct misspellings with query suggestions or tailor the search recommendations to bring back the most appropriate items based on the click-throughs of previous users.
Machine Learning
Machine Learning – A field of artificial intelligence, focused on the creation of algorithms, models and systems to perform tasks and generally to improve upon themselves in performing that task without being explicitly programmed.

Search Algorithms
There are different types of algorithms for different machine learning problems. Each enterprise search solution organization has their own breakthrough in developing relevant ML capabilities. We will only cover here a few to name,
RankBrain
RankBrain is a machine learning-based search engine algorithm, the use of which was confirmed by Google on 26 October 2015. It helps Google to process search results and provide more relevant search results for users.
In short, RankBrain helps the algorithms apply their signals to things instead of keywords.
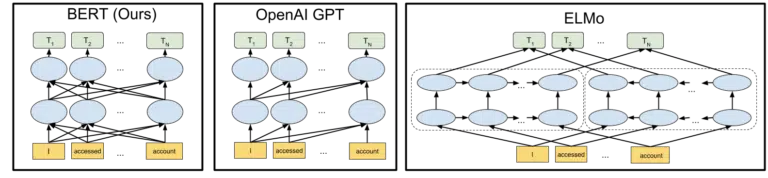
BERT (Bidirectional Encoder Representations from Transformers).
With BERT, Where previously a model could only apply insight from the words in one direction, now they gain a contextual understanding based on words in both directions.
LaMDA
LaMDA is a conversational language model, that seemingly crushes current state-of-the-art
KELM
Rather than being a model, KELM is more like a dataset. Basically, it is training data for machine learning models.
MUM
MUM stands for Multitask Unified Model and it is multimodal. This means it “understands” different content formats like test, images, video, etc. This gives it the power to gain information from multiple modalities, as well as respond.
Google FLAN
FLAN stands for Finetuned LAnguage Net, and describes a method for improving zero-shot learning for Natural Language Processing (NLP) models by using natural language instructions (instruction tuning) by making use of pretraining, finetuning and prompting.
For enterprise search solution, use the latest advancements in machine learning such as vector search, text classification, data annotation, training models for your datasets.
Ways Search engine use ML
Each of the enterprise search solution use ML to provide ways to connect to user to the content they are searching for. Named entity recognition, clustering and classification, and head/tail analysis are some AI/ML techniques that can be useful for faceted searches, grouping queries, and improving underperforming queries, respectively.
Streaming
Streaming allows the solution to operate differently than normal. Search solutions usually show the most relevant results at the top but that can be very resource intensive. Streaming enables the platform to display results in the order that they are actually retrieved but based on the defined conditions.
Query pipelines
Query pipelines allow implementers to change queries in stages and to change the data that is returned. The stages approach is a critical tool to use in order to handle complex data or complex queries or to provide behavior profiling functionality.
Named entity recognition
Named entity recognition (NER) is the use of natural language processing (NLP) to recognize the names of companies, individuals or other proper nouns. This feature can be useful for various types of filtered or faceted search.
Clustering and classification
Clustering and classification are machine learning techniques that allow data or queries to be grouped or labeled automatically.
Head/tail analysis
Head/tail analysis is a machine learning technique that identifies and rewrites underperforming queries to be more like similar well-performing queries.
Vector Search
Lucene’s vector fields and approximate nearest neighbor (ANN, using HNSW) search, matching search queries with vector-based search concepts that make search applications faster and more accurate — especially at scale.
NLP support
Support for modern natural language processing lets you use it for sentiment analysis, text classification, and named entity recognition (NER). Bidirectional Encoder Representations from Transformers – BERT, for short uses to better understand the context of a user’s search query.
Predictive models
Use predictive models (supervised learning) to classify data into categories or to forecast trends.
Multimedia search
Enterprises collect huge amounts of image and video content that are usually not searchable. A modern enterprise search needs to be equipped with AI and NLP to convert this unstructured data into searchable content.
It also should leverage custom AI vision services to identify objects like people, places, text etc. that may be present in images and videos.
Multilingual Search
The ability to deliver search results in multiple languages and cater to the language needs of employees across the globe.
Data Ingestion
In choosing an enterprise search platform, organizations must ensure that it supports the data sources that they currently have in place today and in the future. Data source connectors are an important piece of most search solutions.
Parsers work in conjunction with data source connectors to process the data that comes back and turn it into documents. Pipelines are used to connect data sources, parsers and stages of logic used to manipulate data into well-formed documents.
Speed
Finding the right content at speed is the only way. In line with changing user experience across devices and platform, enforce the solution need to be lightening fast for initial results.
From initial auto suggestion, search as you type, spell corrections to NLP capabilities and ranking for recommendation all should be performing well in real time.
Analytics and Insights
Search analytics can provide information on user behavior and what they are looking for. We need insights into how users are interacting with different functions. We should be able to track individual user if needed. With the help of the analytics, they can also realize their conversion goals and see how things are changing over time. We should be able to take steps to improve user adoption and accordingly make user experience more effortless.

Access all of your search data in shareable dashboards that help your team monitor performance, pinpoint issues, track patterns, identify trends, and optimize the search experience.
Capture ClickStream Data
Capture User queries, clicks, adds, purchases and other similar clickstream data. This may include user location, vector, altitude or any number of event type data.
Track Individual Customer
Usage analytics allow implementers to inspect how users interact with search and may even allow inspecting the actions of an individual customer.
Analytics Tools Integration
Enable integration points with your proprietary analytics platform — Tableau, Power BI, Excel, SQL Workbench, or others. Use analytics endpoints to make requests against queries, clicks, counts, and logs using the analytics APIs.
Improve Customer Experience
Analytics tool to allow action to improve consumer experience by reviewing query and click analytics captured automatically in an easy-to-understand dashboard to understand how to tune search quality and give end-users exactly what they’re looking for.
Optimizations and Tuning
Optimize contextual relevance and personalization in real time with precision tuning, weights, boosts, and automated search result promotions powered by machine learning. The search solution should enable business to fine tune the configurations to enrich customer experience to archive the business value.
Search testing
The platform should enable experimenting around multiple search configurations to see which configuration works best? Set one variant up against another to verify which level of tuning provides the best experience and results for your business.
Rules when you need them
The search solution should enable to build time-bound campaigns or program ranking rules without the help of developers. The platform should provide the ability to easily alter and optimize featured results and ranking expressions.
Fix low-performing queries
Consistently deliver relevant results despite query misspellings and product variances.
No more zero results pages
Use advanced semantic search capabilities to avoid zero result scenario and understand user context and intent better to show relevant information.
Operational Capabilities
Scalability, High Availability, and Disaster Recovery
Scalability is one of the must-have capabilities for your enterprise search solution. Other capabilities like high availability and disaster recovery are also important in the event of network outages, fibre cuts, or any calamity.
System monitoring
Modern search solutions provide statistics about system performance and uptime, including graphical displays and dashboards.
A/B testing
Show admins whether changes to search pipelines or other functionalities improve search performance for users. Enable directed tested scenarios for features or campaign to taken necessary judgement calls on the product.
Security
Modern enterprise search platforms ensure security especially given the large quantities of data that they deal with. Some of the practices include connectivity to major security technologies, role-based security authorization, and document-level security. By limiting access to only the people that need it, enterprises can optimize security.
Connectivity to major security technologies like Active Directory, LDAP, Kerberos and SAML or other single sign-on systems is critical to a search solution’s security capabilities.
Role-based security authorization to determine which users are allowed to delete, read, modify or create documents as well as enact system changes.
Document-level security methods like security trimming to allow for fine-grained control to ensure that users don’t see documents they don’t have access to as a query result.
Enterprise Search Solutions
There are many commercial enterprise solutions in the market, Choose an enterprise solution best fitting to your needs,

Amazon Kendra
Coveo
Elastic Workplace Search
Google Cloud Search
IBM Watson Discovery
Lucidworks Fusion
Microsoft Search
etc.
The list is only for reference and not per priority or ranking. There are equally good many more such products.
I hope the details give you a bit better perspective regarding the enterprise search solution capabilities. We have not gone in details for each of those category, but it sets the base for you to explore further and dig deep further.
Next…
In the upcoming posts, we will be covering further how search solutions fit best to Healthcare domain requirements. And the user interactions and data set commonly used. How to optimize the AL/ML capabilities to strengthen the user journey. Stay tuned!

Leave a comment