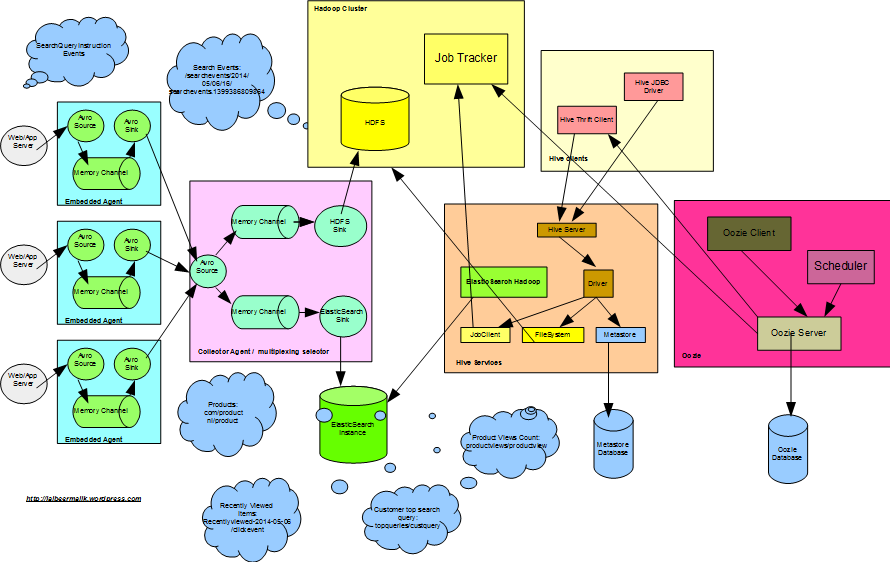
In this post we will explore HBase to store customer search click events data and utilizing same to derive customer behavior information based on search query string and facet filter clicks. We will cover to use MiniHBaseCluster, HBase Schema design, integration with Flume using HBaseSink to store JSON data.
In continuation to the previous posts on,
- Customer product search clicks analytics using big data,
- Flume: Gathering customer product search clicks data using Apache Flume,
- Hive: Query customer top search query and product views count using Apache Hive,
- ElasticSearch-Hadoop: Indexing product views count and customer top search query from Hadoop to ElasticSearch,
- Oozie: Scheduling Coordinator/Bundle jobs for Hive partitioning and ElasticSearch indexing,
- Spark: Real time analytics for big data for top search queries and top product views
We have explored to store search click events data in Hadoop and to query same using different technologies. Here we will use HBase to achieve same,
- HBase mini cluster setup
- HBase template using Spring Data
- HBase Schema Design
- Flume Integration using HBaseSink
- HBaseJsonSerializer to serialize json data
- Query Top 10 search query string in last an hour
- Query Top 10 search facet filter in last an hour
- Get recent search query string for a customer in last 30 days